What is a client?
Clients are unique applications, services, and/or users that authenticate to a HashiCorp Vault cluster.
For billing and consumption, only unique and active clients during the billing period (monthly in the case of HCP, and annual in the case of self-managed platforms) are counted towards totals. Each client is counted just once within a billing period, no matter how many times it has been active. Once authenticated to a cluster, the clients have unlimited access to that cluster for the remainder of the billing period.
More on clients
Ultimately, clients represent anything that has authenticated to Vault to do something. Users are people who login into the cluster to manage policies, set up dynamic secret rotation, and more. So every user that logs into the Vault is considered a client. Furthermore, every application, service, or any other machine-based system that authenticates to Vault is also considered a client.
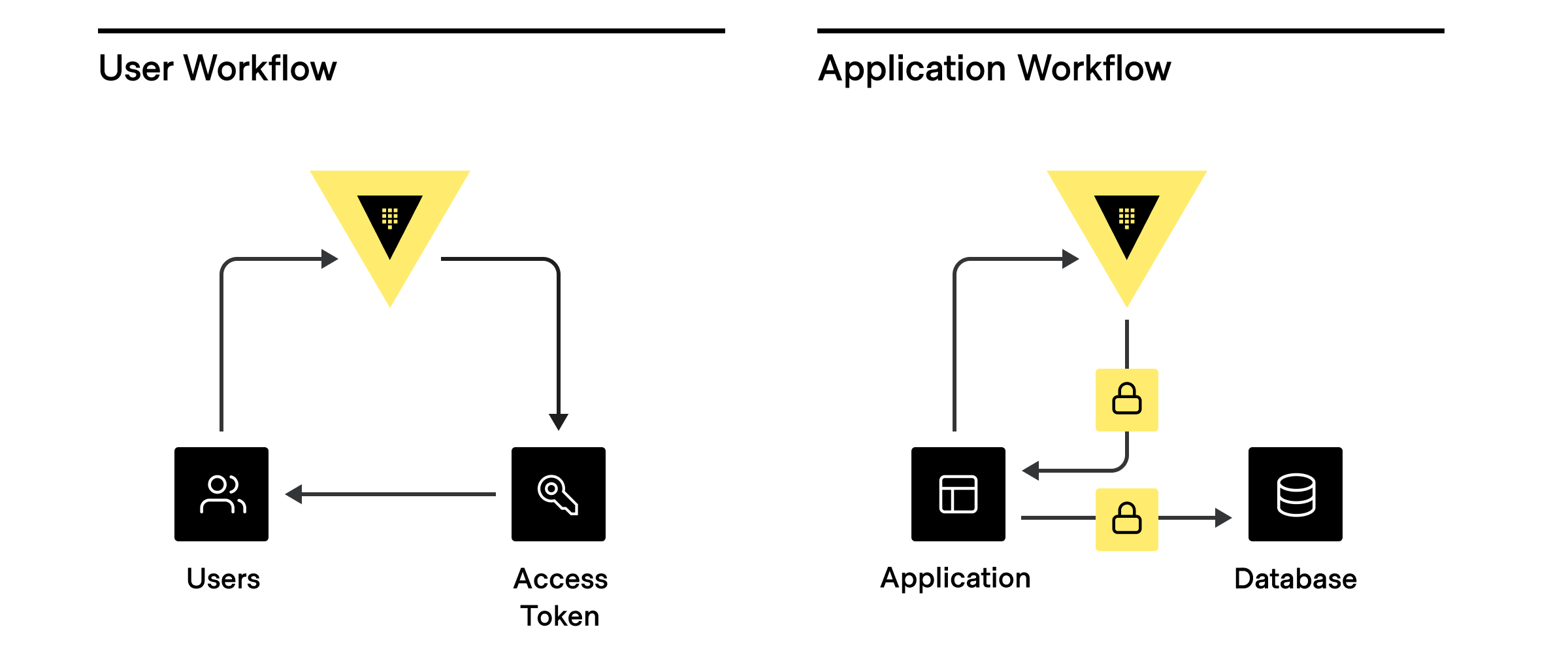
There are three main ways clients are assigned an identity:
- External Identity Management Platform or SSO: Active Directory, LDAP, OIDC, JWT, GitHub, Username/password, etc.
- Platform or server-based identities: Kubernetes, AWS, GCP, Azure, PKI, Cloud Foundry, etc.
- Self Identity: AppRole, tokens (without an associated auth path or role)
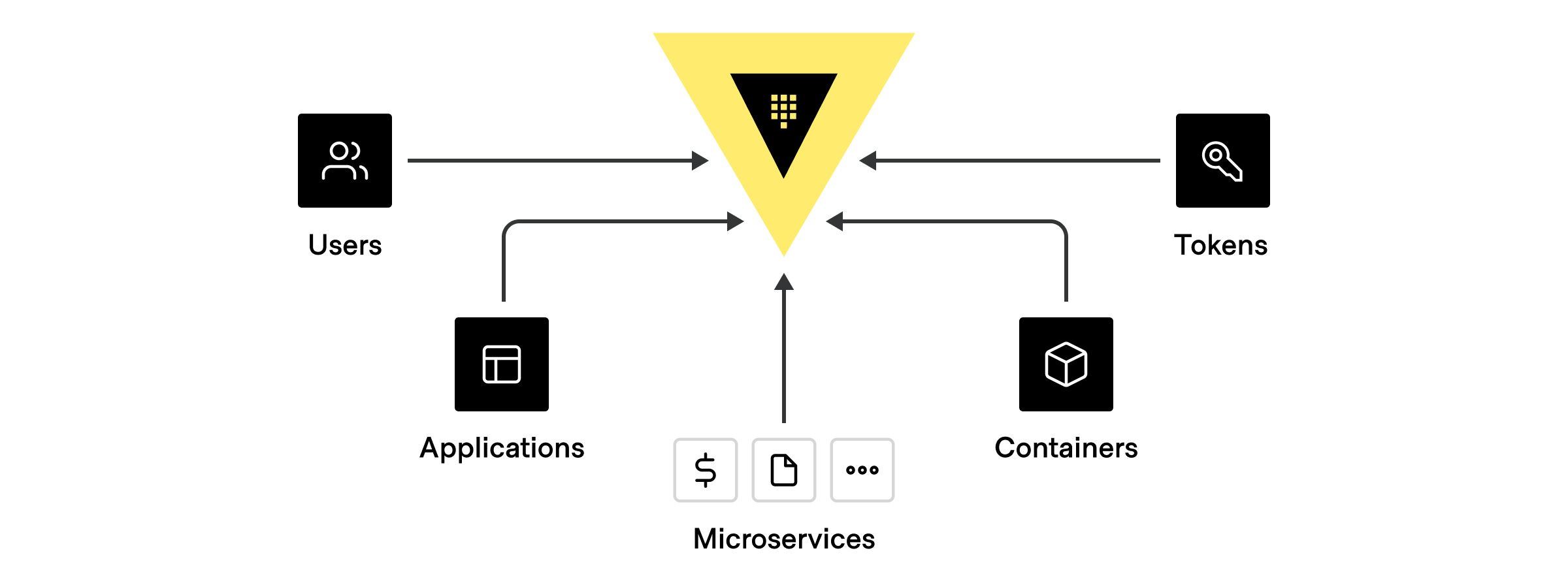
There can be many different types of clients that authenticate and communicate with Vault using one of the above identities, including:
- Human users: GitHub ID, username/password, LDAP, Active Directory, Kerberos, JWT/ OIDC claims, OKTA
- Applications or Microservices: 2-Factor Authentication methods such as AppRole, LDAP, Active Directory, or based on the platform’s identity, such as credentials from AWS, Azure, GCP, AliCloud, OCI, Kubernetes, Cloud Foundry, etc.
- Servers and Platforms: VMs, Containers, Pods (Identified by LDAP, Active Directory service accounts, AWS, Azure, GCP, AliCloud, OCI, Kubernetes, TLS Certs).
- Orchestrators: Nomad, Terraform, Ansible, or Continuous Integration Continuous Delivery (CI/CD) Pipelines where each pipeline is usually identified by 2FA methods, App Role, or platform-based identity.
- Vault Agents: Acts on behalf of an app/microservice, typically identified by App role, Cloud credentials, Kubernetes, TLS Certs.
- Tokens: Not tied to any identities at all. These should be used sparingly. Hashicorp recommends associating tokens to an entity alias and token role at all times.
How do clients work in Vault?
When a client authenticates to Vault, whether a user, application, machine, etc., it is associated with a unique entity within the Vault identity system. The name reported to the identity systems by the different authentication methods types varies (list below), and each entity is created or verified during authorization. There are scenarios where tokens can be created outside of the identity system without an associated entity. In this scenario, these tokens are considered clients. For production usage, it is uncommon to have any tokens created outside of the identity systems.
But wait, there’s more...
Want to take full advantage of the Vault identity system and how clients are counted? The Vault identity system also has Entity Aliases and Identity Groups.
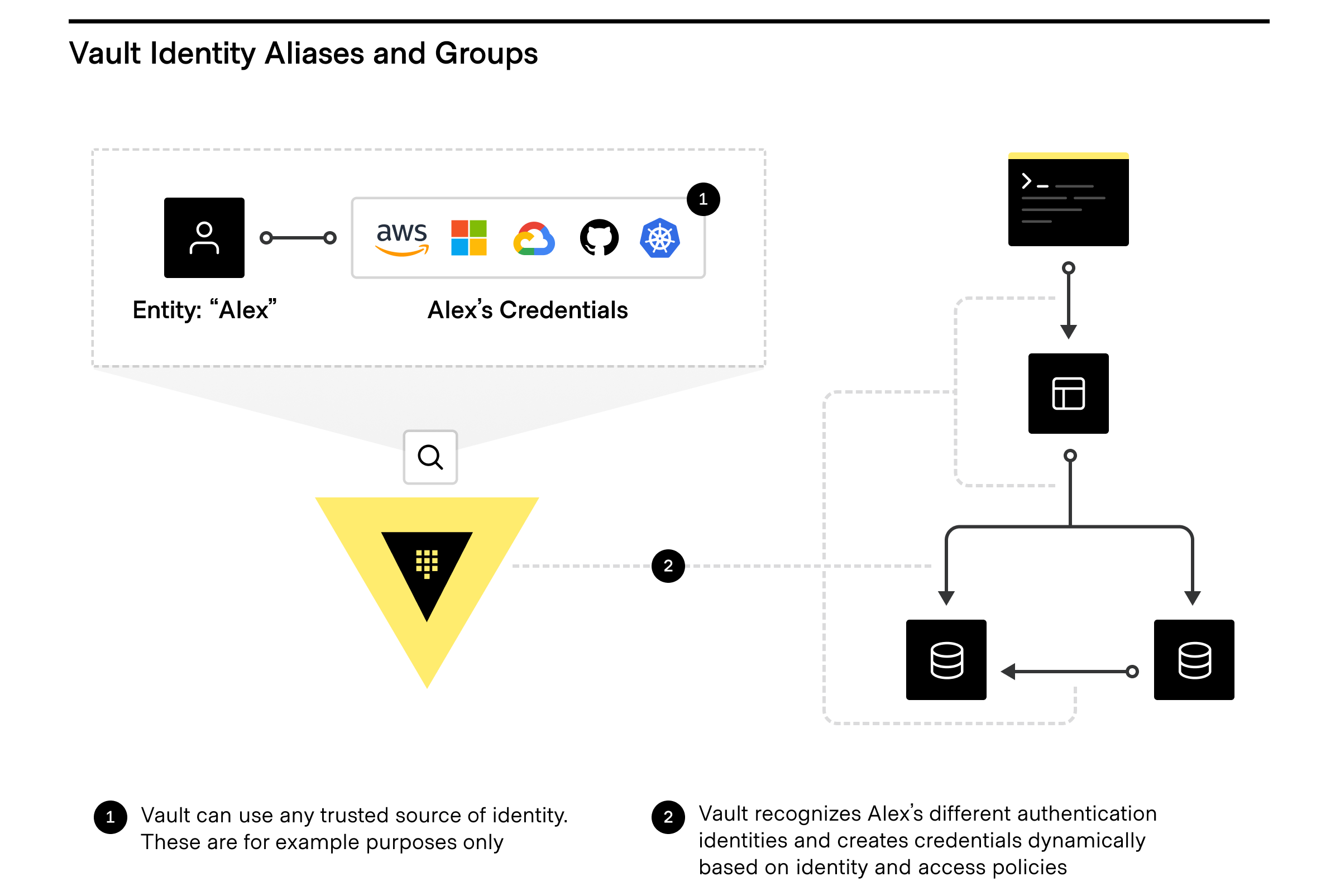
Entity aliases
Entity Aliases enable users or services to authenticate with more than one method and are associated with the same policy to share resources and count as unique entities.
Identity groups
Identity Groups within Vault leverage entities where Vault enables teams to create and manage logical groupings of entities. Identity Groups can be based on organizations or teams within companies, and can be used to assign policies and metadata, making user management dramatically simpler, especially for automating workflows by using Identity Groups to quickly and easily grant access to secrets and functionality within Vault.
For more on managing access with identity, entities, and more, refer to Identity-based Security and Low-trust Networks and the HashiCorp Learn tutorial Identity: Entities and Groups | Vault
Secrets Sync
The Secrets Sync functionality could increase an account's overall client count and therefore an organization could incur additional costs. An organization will not incur additional costs by only activating the Secrets Sync feature. However, individual secrets configured to actively sync are treated as clients and therefore have the opportunity to increase an organization's overall client count. This increase in clients will cause increased costs to be incurred.
Activating the Secrets Sync feature can be done through one of several methods. One option is by activating it through the UI directly. Alternatively, the endpoint sys/activation-flags/secrets-sync/activate can be used by either issuing a POST/PUT request to it or via the CLI with the command vault write -f sys/activation-flags/secrets-sync/activate.
Learn more about the Secrets Sync feature.
How does Vault avoid counting the same entity twice?
Using the identity system allows Vault to make sure that entities are not counted more than once. Once you determine the identity and authentication method to use for each human, application, platform, and CI/CD pipeline, upon authentication for the first time in a billing period, Vault instantiates a unique entity. For example, say you have an application “AppX” that needs to get a secret from Vault using the AppRole method. Since AppX has an associated entity within Vault with associated policies, Vault knows every time that AppX is authenticating and authorizing, so AppX is only counted once.
Non-entity tokens
If you choose to use the Token Auth Method without an identity, a non-entity token always assigns each token to a role and entity alias. HashiCorp recommends creating a Token Role first, with allowable entity aliases and issuing your token with the appropriate role and entity alias name. This is the name that will uniquely identify the client, no matter how many tokens are issued. Without this, each token will be counted as a client instead. For further information, please refer to the changes reflected in the 1.9 release notes or check out our learn guide.
Differences between a direct entity and a non-entity token
While the definition of clients appears to be simple on the surface, there are many nuances involved in the computation of clients. As mentioned, clients are unique applications, services, and/or users that authenticate to a Vault cluster. When anything authenticates to Vault, it is associated with a unique identity entity within the Vault Identity system. The name reported to the identity systems by the different types of authentication methods varies, and each entity is created or verified during authorization.
One thing to note is that Vault clients are a combination of active identities as well as non-entity tokens. Identity entities are unique users, and when identities authenticate to Vault, corresponding tokens are generated. However, there are some situations in which tokens are generated without corresponding identities (e.g., when using the token auth method to create a token for someone else whose identity is unknown). As such, these non-entity tokens also represent users, and are counted towards the overall client aggregates. Here are some situations in which non-entity tokens get created within Vault.
- Tokens within Vault are the core method for authentication. You can use Tokens to authenticate directly, or use the auth methods to dynamically generate tokens based on external identities.
- There are scenarios where tokens are created outside of the identity system without an associated entity. For this reason, unique identity entities alone cannot always add up to the total unique authentications made to Vault over a stipulated time period.
- In a scenario where tokens are created outside of the identity system, these tokens are considered clients. Note that it should be rare for production usage to have any tokens created outside any identity systems.
- There are a few ways of creating tokens without entities: Token Roles, Token Create APIs, Wrapping Tokens, and Control Groups. For more information, refer to the What is a Client? documentation.
Client counts are not computed solely using a combination of unique identity entities within Vault but also computed using a combination of unique identity entities and non-entity tokens.
Considerations for namespaces
Since namespaces represent logical isolations within a single Vault cluster for administrative purposes, consideration must be made on how Vault clients are determined in this context.
- If a client authenticates to Vault in a parent or root namespaces, it is considered the same client in all child namespaces. This is obvious as it is within the same logical isolation.
- However if a client authenticates to Vault in two separate namespaces, because of logical isolation they are not considered as the same client. As an example,
/namespaceA/ldap/auth/login/bobis not related to/namespaceB/ldap/auth/login/bob. If the intent is that “Bob” is the same client, authenticate into two namespaces:- Move the auth to the parent workspace and any auth to child namespaces would be considered as the same client
- Place that auth in the root namespace to be considered as 1 client in all namespaces.
See also the guide Secure Multi-Tenancy with Namespaces | Vault.
Onboarding clients - putting it all together
This guide, “Onboarding Applications to Vault Using Terraform: A Practical Guide“ is a very good example on how to build an automated HashiCorp Vault onboarding system with Terraform to accommodate Vault client using sensible naming standards, ACL policy templates, namespaces, pre-created application entities, and workflows driven by VCS and CI/CD.
Authentication methods and how they’re counted in Vault
Below is a list of supported authentication methods within Vault. You can also set up custom auth methods with secure plugins.
Each authentication method has a unique identifier to determine a unique identity, similar to a driver's license number that determines an identity with a driver’s license.
How does this relate to Vault clients? As outlined above, and as an example, if you chose to identify a microservice by AppRole auth method, then assign a role id for that microservice. A role id is the mircoservice’s username and identity. It would be best to have microservices use different role ids . However, if microservices (or multiple VMs, or containers) are exact copies using the same role id, they will all have the same identity. This is the appropriate security posture to mitigate any risk, and an operator can easily approve or deny access to secrets for that one role id without affecting other services. It is important as you choose an identity for each human, app, service, platform, server and pipeline, that you pay attention to the name below that makes each method unique and be given an identity.
| Auth method | Name reported by auth method |
|---|---|
| AliCloud | Principal ID |
| AppRole | Role ID |
| AWS IAM | Configurable via iam_alias to one of: Role ID (default), IAM unique ID, Full ARN |
| AWS EC2 | Configurable via ec2_alias to one of: Role ID (default), EC2 instance ID, AMI ID |
| Azure | Subject (from JWT claim) |
| Cloud Foundry | App ID |
| GitHub | User login name associated with token |
| Google Cloud | Configurable via iam_alias to one of: Role ID (default), Service account unique ID |
| JWT/OIDC | Configurable via user_claim to one of the presented claims (no default value) |
| Kerberos | Username |
| Kubernetes | Configurable via alias_name_source to one of: Service account UID (default), Service account name |
| LDAP | Username |
| OCI | Rolename |
| Okta | Username |
| RADIUS | Username |
| TLS Certificate | Subject CommonName |
| Token | entity_alias, if provided (Note: please ensure that entity_alias is always used) |
| Username/Password | Username |
Considerations with CI/CD
Orchestrators and Continuous Integration Continuous Delivery (CI/CD) Pipelines such as Nomad, Terraform, Ansible, and the like, along with CI/CD tools such as Jenkins, Bamboo, Azure DevOps, GitLab, and GitHub Ops, and such, can be used to authenticate to and request secrets from Vault during infrastructure or application/service deployment. While the discussion below focuses on CI/CD, it is also applicable to orchestrators.
A CI/CD workflow can encompass many pipelines. Let's take a look at the following considerations and determine the best option to secure your workflow:
- Option 1: Master CI/CD identity: Provide the overall CI/CD orchestrator with a master identity (e.g., app role, token with an entity alias) to authenticate to Vault and receive all secrets for all pipelines and applications/infrastructure deployed. From a Vault perspective, the Master CI/CD identify is considered as one client.
- Option 2: Pipeline Identity: Provide every CI/CD pipeline with an identity (e.g., app role, token with an entity alias) to authenticate to Vault once and receive all secrets for each application/infrastructure deployed. From a Vault perspective, the Master Identity CI/CD identity is one client, and each pipeline is one client.
- Option 3: Pipeline and App/ Service/ Infra identity: Provide every CI/CD pipeline with an identity (e.g., app role, token with an entity alias) to authenticate to Vault once, and then give each application/service/infrastructure deployed workflow its own identity. Upon bootstrapping, application/services/infrastructure authenticates to Vault and retrieves a secret. From a Vault perspective, the Master CI/CD identity is considered as one client for each pipeline, and one for each application or service deployed.
From a threat model and security assessment perspective, Option 3 is considered the most secured approach, as this model lets you revoke an application or service without affecting everything else.
On the other hand, Option 1 and Option 2 are considered less secured models. For instance, for Option 1, if you have to revoke access for any reason, CI/CD pipelines are affected and you run the risk of someone gaining access to your CI/CD workflow pipeline. Similarly with Option 2, if you revoke access to a pipeline, only that pipeline is affected, and you limit your security risk. However, you run the risk of someone obtaining access to your pipelines and gaining access to every or some secrets used by your applications and services.
Carefully reviewing these considerations and security options is highly recommended when deciding on a security model that best fits your organizational needs. Using the principle of least privilege, where you only want to give access to secrets where necessary, there should be little or no gap between your secrets distribution and when it is accessed. Therefore, you should avoid inadvertently giving your orchestrator and CI/CD tool privileges where it can be used to potentially access every secret for every app, service, or infrastructure you deploy.